
If you started using Claude Opus 4.7 and noticed your quota draining far faster than before — even though your workflow hasn’t changed — you’re not alone. I hit the exact same wall right after release, and after testing settings, model swaps, and tool combinations, I landed on a routine that delivers real Opus 4.7 token reduction without sacrificing output quality. Just rolling /effort back to medium roughly doubled how long my Max 20x quota lasted, and once I capped Opus 4.7 usage at about 50% of my workload the meter stopped getting dangerously close to zero. This guide walks through the fixes that actually moved the needle, ordered by impact.
📑Table of Contents
The short version: tune /effort, switch models per task (Opus 4.6 and Sonnet alongside 4.7), and pair Claude with ChatGPT. Right after release, /effort behaved as if pinned near xhigh, which inflated thinking tokens hard. Running everything on Opus 4.7 burns the meter quickly, so route work by purpose and the difference is dramatic.
| Tactic | Impact | Effort | Caveat |
|---|---|---|---|
Drop /effort to high/medium | High | Easy | May reduce quality on hardest tasks |
| Trim input context | Medium | Medium | Trim too much and you lose context |
| Mix in Opus 4.6 | High | Easy | Stay on 4.7 for code gen |
| Mix in Sonnet 4.6 | High | Easy | Less reasoning depth than 4.7 |
| Pair with ChatGPT Pro | High | Medium | Extra $200/month |
| Build prompts & skills | Medium | Medium | Upfront investment required |
Source: Anthropic — Claude Opus 4.7 announcement and the author’s hands-on usage (April 2026).
Why Opus 4.7 burns more tokens
The headline reason 4.7 feels heavy is a combination of post-release /effort behavior and the fact that 4.7 is engineered to think longer and deeper. The official Opus 4.7 announcement highlights “rigorous handling of long-running tasks” and “self-verification” as headline gains. Both are great for quality, but they also thicken the pre-output thinking layer.
The other piece that’s easy to miss is the new tokenizer. Anthropic itself notes that the same input text can map to more tokens than under 4.6, and external analysis pegs the upper end of that drift at roughly 1.35x for code, structured data, and non-English text. List prices are unchanged ($5 / 1M input, $25 / 1M output), but your actual bill on the same workload can quietly tick up. That’s the rational basis for hitting the meter from the settings side.
From my own logs, the moment I jumped on 4.7 in Claude Code, replies became oddly clipped — the polite phrasing I was used to vanished and the responses turned bluntly minimal. Digging in, I found /effort sitting on xhigh — and I had not changed it. Setting it back to medium immediately calmed both the burn rate and the tone of the replies. The most likely explanation is that the default behavior shifted unexpectedly right after launch. Hex, an early-access partner, even noted publicly that “low-effort 4.7 is roughly equivalent to medium-effort Opus 4.6,” which tells you how sensitive effort tuning has become.
API note for migrators: Opus 4.7 also removes the manual thinking.budget_tokens field in favor of thinking.type="adaptive" plus output_config.effort. Non-default values for temperature, top_p, and top_k now return 400 errors, so harnesses that worked on 4.6 will need adjustment before pointing at 4.7.
The takeaway: this isn’t a “bad model” story; it’s a mismatch between effort and the task at hand. Realigning settings and model choice is enough to recover most of your budget. For a deeper dive, see Claude Opus 4.7 Released — Improvements and the /effort xhigh Default Saga.
Reduction tactics I actually use
Below is the order I run through, ordered by impact. All of it was tested on the Max 20x plan during April 2026.
Audit your /effort first
Check the current /effort value. If it’s still xhigh or max, drop it to high or medium. Code generation and tricky bug fixing are well served by high; for research, summarization, and short answers, medium is plenty. In my workflow, going from xhigh back to medium alone was enough to stretch how long my daily quota lasted by roughly 2x. Switching effort per task — xhigh only when it really matters, medium otherwise — is the realistic sweet spot.
Use Claude Code’s /token and /cost slash commands to see your current consumption and dollar-equivalent cost in-session. Glancing at those numbers before and after each /effort change makes it obvious which tactics are actually moving the needle.
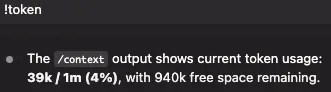
/token: current token usage at a glance
/cost: dollar-equivalent burn in real timeTrim input context (context engineering)
Don’t paste whole files when an excerpt does the job. Compact long sessions with /compact before continuing, and consolidate standing rules into CLAUDE.md so you stop reshipping the same explanation each turn — which also helps prompt caching. Solo, the impact is moderate; combined with the other tactics, it multiplies.
Know the per-model price card
Routing decisions get easier once you can see the per-token unit cost and the intended use of each model side by side. The April 2026 Anthropic API pricing and primary use cases:
| Model | Input ($/1M) | Output ($/1M) | Context | Best for |
|---|---|---|---|---|
| Claude Opus 4.7 | $5 | $25 | 1M | Hard code gen, long-running agents, vision |
| Claude Opus 4.6 | $5 | $25 | 1M | Design review, doc work (effectively lighter than 4.7) |
| Claude Sonnet 4.6 | $3 | $15 | 1M | Day-to-day code gen, formatting, summarization, RAG |
| Claude Haiku 4.5 | $1 | $5 | 200K | High-volume, low-latency extraction / routing |
Sources: Claude pricing page, Finout — Claude Opus 4.7 Pricing 2026 (April 2026).
Sonnet costs about 60% of Opus on both input and output; Haiku is roughly one-fifth. Anything you can move off Opus translates straight to a lower bill.
Bring Opus 4.6 back into rotation
In my workflow, anything that doesn’t touch code — spec drafts, design-review comments, blog outlines — goes to Opus 4.6. I keep Opus 4.7 usage at roughly 50% of my workload, and that single shift was enough to keep the Max 20x meter from running dry on busy days. 4.6 is still served as claude-opus-4-6 at the same price tier, so leaving 4.7 to handle hard code generation and routing the rest to 4.6 just works.
Push routine code generation to Sonnet 4.6
My current split is to do the up-front planning and design on Opus 4.7, then hand the actual code generation to Sonnet. The hard part — making sure the plan won’t break downstream — is what 4.7 is good at. Once that’s locked in, Sonnet writes the code without drama and at a fraction of the meter cost. Asking “does this really need Opus?” before every task is the habit that paid off the most for me. The Opus you save is the Opus you get to spend on the hard problems.
Pair with ChatGPT Pro (GPT-5.5)
The “always Claude” tasks for me are the ones that come before code generation: requirements work, architectural decisions, and reviewing the gnarly parts of a design. Bulk code generation and test writing then go to ChatGPT Pro (GPT-5.5), and when ChatGPT usage starts climbing too I split that further with Sonnet — a three-tier rotation. Together, Claude Max 20x and ChatGPT Pro run me about $400 a month, but the throughput feels closer to several thousand dollars worth of work. “Claude + GPT” reliably reduces both wait time and total spend more often than “Claude only” did.
If you still need more headroom
If your meter still feels tight after the core tactics — usually due to long sessions or heavy image input — these complements help.
Place large static context (specs, coding standards) where it can be cached. Cache reads bill at roughly 10% of the standard input rate — up to 90% off the input side.
Nightly backfills, evaluation sweeps, and summarization jobs that tolerate minutes-to-hours latency get 50% off via the Batch API and dodge real-time rate limits.
/compact proactivelyLate-session thinking tokens balloon; compact at clean breakpoints.
4.7’s high-res vision is strong but token-heavy. Crop and downsize screenshots.
Stop re-doing the same parsing in prompts. See Claude Hooks Guide.
Wrap “task type → model + effort” into a skill so the model picks for you.
Plan-by-plan strategy
The same Opus 4.7 token reduction tactics weight differently per plan. Here’s how I’d prioritize on each, calibrated against my Max 20x usage.
| Plan | Monthly | Recommended use |
|---|---|---|
| Pro | $20 | Opus 4.7 for crunch only. Sonnet for daily, 4.6 for research. |
| Max 5x | $100 | 4.7 as primary, route routine work to Sonnet/4.6. |
| Max 20x | $200 | 4.7 holds up alone, but mixing in 4.6/Sonnet shortens wait time. |
| Team / Enterprise | Contact sales | Standardize a team-wide /effort guideline. |
Source: Claude pricing page (April 2026).
If you’re rethinking the plan itself, see Claude pricing plans explained and Is Claude Max worth it?.
FAQ
What’s the recommended /effort setting?
Default day-to-day to medium, jump to high for code generation or hard fixes, and reserve xhigh for genuinely difficult design calls. max is rarely worth it. In my own usage, just rolling xhigh back to medium roughly doubled how long the daily quota lasted.
Is Opus 4.6 still available?
Yes. As of April 2026, the API model ID claude-opus-4-6 is still served. Note that Anthropic’s rate limit for Opus is pooled across 4.7 / 4.6 / 4.5 / 4.1 / 4, so falling back from 4.7 to 4.6 doesn’t unlock a separate quota — it draws from the same Opus bucket.
Sonnet vs. Opus 4.6 — which should I pair with 4.7?
Use 4.6 when reasoning depth matters; reach for Sonnet when speed and cost dominate. I personally route doc-style work to 4.6 and code generation to Sonnet.
My usage spiked overnight — what’s the first thing to check?
Inspect /effort (it shouldn’t be sitting on xhigh/max) and confirm long sessions are getting /compact‘d. Pair this with the in-session /token and /cost commands to see hard numbers.
Does ChatGPT Pro really pay for itself?
For developers who regularly drain Claude Max, yes. The split that works for me — design and pre-implementation thinking on Claude, bulk implementation and tests on ChatGPT — runs about $400/month combined and feels like several thousand dollars of throughput.
Which tasks justify Opus 4.7?
Hard code generation, long-running tasks that benefit from self-verification, and visual analysis — anywhere 4.7’s improvements show up.
How much does prompt caching help?
For workloads with large static prefixes, cache reads bill at roughly 10% of the standard input rate, which translates to up to 90% off the input side. Gains are modest in highly dynamic conversations.
Wrap-up
Opus 4.7 token reduction comes down to settings, model choice, and division of labor.
Pull /effort back to medium–high, mix Opus 4.6 and Sonnet into your routine, and pair with ChatGPT Pro when the workload calls for it. The “use 4.7 for everything” pattern is the most expensive way to use Claude in 2026 — task-level optimization is the new default.
Related: Claude Opus 4.7 Release Guide / Claude Code Productivity Techniques / Claude Code Skills Guide

Author
krona23
Over 20 years in the IT industry, serving as Division Head and CTO at multiple companies running large-scale web services in Japan. Experienced across Windows, iOS, Android, and web development. Currently focused on AI-native transformation. At DevGENT, sharing practical guides on AI code editors, automation tools, and LLMs in three languages.



Leave a Reply