
Claude Opus 4.7 became generally available on April 16, 2026, and it is a clear step up from Opus 4.6 in self-verification, long-running tasks, vision, and the hardest coding work. Right after the release, however, two distinct complaints showed up at the same time on Claude Code: replies suddenly felt blunt and lost their usual polite tone, and token consumption shot up to several times the previous baseline.
📑Table of Contents
- What is Claude Opus 4.7? The April 16, 2026 Opus refresh
- The four real wins in Opus 4.7
- My experience: the “blunt” feel and the token spike are two different problems
- How it played out: noticing, isolating, and the eventual fix
- Three migration pitfalls to clear first
- Three settings to verify right now
- How Opus 4.7 sits next to GPT-5.4 and Gemini 3.1 Pro
- Should you upgrade to Opus 4.7?
- Frequently asked questions
- Summary
In my reading of the Opus 4.7 Claude release, these are two separate issues, not one. The “blunt” feel is the side effect of Anthropic adding a system prompt that tries to shorten output tokens, while the cost spike is driven by a new tokenizer and the way /effort tiers behave — they just happened to land together. This article first goes through the genuine improvements in 4.7, then walks through the real source of each complaint, the migration pitfalls that bite API users, and the three settings worth re-checking right now.
| Dimension | Opus 4.6 | Opus 4.7 |
|---|---|---|
| Hard coding tasks | Baseline | +13% on Anthropic’s 93-task internal bench, ~87.6% on SWE-bench Verified (reported) |
| Self-verification | Limited | Reviews its own logic before output |
| Long-running tasks | Reasonably stable | More consistent and complete |
| Vision | Standard resolution | Up to 2576px / 3.75MP image input |
| API price (input / output) | $5 / $25 per Mtok | $5 / $25 per Mtok (unchanged) |
| Real-world cost trend | Baseline | Same sticker price, but a new tokenizer plus higher-effort defaults can lift real spend up to ~35% |
| API model ID | claude-opus-4-6 | claude-opus-4-7 |
Source: Anthropic official announcement, Karo Zieminski’s hands-on review (as of April 2026)
What is Claude Opus 4.7? The April 16, 2026 Opus refresh
Claude Opus 4.7 is Anthropic’s latest publicly available Opus-class model, released on April 16, 2026. It is the most capable Opus you can use today, but Anthropic notes that Claude Mythos — a more capable research preview — sits above it internally; Opus 4.7 was deliberately released with somewhat reduced cybersecurity capabilities so that new safeguards can be validated on a less powerful model first.
It is available across Claude.ai, the Anthropic API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. The API model ID is claude-opus-4-7, and pricing stays at $5 per million input tokens and $25 per million output tokens — identical to Opus 4.6. For most teams, switching is a one-line model ID change, although a few API parameters were retired at the same time and need cleanup (covered later in this article).
You can read the full announcement at Introducing Claude Opus 4.7. If you also want to map this against subscription tiers, the Claude pricing breakdown is a good companion read.
The four real wins in Opus 4.7
Stripping out the marketing language, the genuine improvements in this Opus 4.7 Claude release fall into four buckets: hard coding, self-verification, long-running consistency, and vision. Each one is grounded in Anthropic’s own announcement, partner quotes, and external review numbers.
1. Stronger results on the hardest coding tasks
On Anthropic’s 93-task internal coding benchmark, Opus 4.7 lifts resolution by about 13% over Opus 4.6 — including four tasks that neither Opus 4.6 nor Sonnet 4.6 could solve. External reviews report Opus 4.7 reaching roughly 87.6% on SWE-bench Verified, which is in line with what you would expect for a model targeted at agentic coding. In day-to-day work, this shows up most clearly on multi-file refactors and on bugs that span multiple layers of the stack, where weaker models tend to thrash.
2. Self-verification before output
Opus 4.7 is much more disciplined about checking its own logic before answering. Hex, an early access partner, highlighted that it correctly reports when data is missing rather than fabricating “plausible-but-incorrect” fallbacks — a class of hallucination that even Opus 4.6 sometimes falls into. Anthropic’s own model card claims meaningful reductions in important omissions and overall hallucination rates compared with Opus 4.6 and Sonnet 4.6. For data and analytics workflows, that single change is often more valuable than the headline coding numbers.
3. Consistency on long-running, multi-step work
Opus 4.7 also holds up better on tasks that run for hours rather than seconds. Devin reports that “long-horizon autonomy” reaches a new level, with the model pushing through hard problems instead of giving up midway. If you orchestrate Opus through autonomous agent workflows like the ones covered in How Claude is automating your PC: Dispatch, Computer Use, Loop, and Channels, this is exactly the dimension you want strengthened.
4. Higher-resolution vision
Vision input is sharper. Opus 4.7 accepts up to 2576px / 3.75MP images and gives noticeably better results on dense diagrams, chemical structures, patent figures, and multi-column PDFs. For practical work — for example, debugging a UI by feeding screenshots into Claude Code — small text and crowded layouts that previously required cropping or re-shooting are now handled in one pass.
5. Same sticker price, real cost can still rise
Pricing did not change, but real spend often does. Anthropic’s own migration guide states that Opus 4.7 “thinks more at higher effort levels” and therefore consumes more output tokens than its predecessor. External reviews of the new tokenizer have observed up to a 35% increase in token count on code-heavy prompts for the same source text. Sticker price stays at $5 / $25 per million tokens, but if you size your monthly budget from list price alone, you will undershoot. Re-baselining with a few representative tasks before the full migration is the safer path.
🏆 Author’s take ― separate the model from the operating cost
In my own testing, the gains on coding, self-verification, and vision are real. But it is much easier to get a clean read on the model when you stop conflating “raw quality” with “what the bill looks like”: Opus 4.7’s quality story and its real-world cost story have moved in different directions, and they deserve separate evaluation.
My experience: the “blunt” feel and the token spike are two different problems
Right after launch, two complaints landed at almost the same time. Treating them as one combined “Opus 4.7 got worse” story is what makes the model look like it regressed; once you split them, both become tractable.
- “Replies feel blunt” — In my reading, this was the side effect of Anthropic adding a system prompt that pushed the model toward shorter output. Replies stopped using their usual polite tone and key reasoning steps got compressed away, which in turn made the answers feel less careful. Anthropic later adjusted this server-side behavior.
- “Tokens are exploding” — A separate story. The new tokenizer counts the same text more aggressively, especially for code, and reasoning-heavy effort tiers stack on top of that. Even with the sticker price unchanged, real bills tend to drift upward.
In my own setup the first signal was the tone shift — replies in Claude Code stopped sounding like the polite, careful Opus I was used to. Almost immediately after, I checked my token balance and saw it draining noticeably faster than usual. It is tempting to glue both observations into a single “Opus 4.7 became blunt and expensive” story, but the system-prompt change and the tokenizer / effort-tier story are mechanically distinct, even though they showed up in the same week.

A quick refresher on /effort
/effort is the Claude Code slash command that selects how much reasoning budget the model is allowed to spend. The tiers are low, medium, high, xhigh, and max; every step up means deeper internal reasoning, more tokens consumed, and higher latency. Opus 4.7 introduces xhigh as an explicit step between high and max. We covered the day-to-day side of this in 15 essential Claude Code productivity techniques.
One useful framing from early testers: “low-effort Opus 4.7 is roughly equivalent to medium-effort Opus 4.6.” With Opus 4.7, you can often drop one tier compared to your old Opus 4.6 routine and still come out ahead. Personally, I have settled on medium as my daily driver and only step up the tier when a task genuinely warrants it — large refactors, bugs that span multiple files, or laying out a long-form article structure.
How it played out: noticing, isolating, and the eventual fix
For the record, here is the actual sequence I went through. It is useful as a template for similar future launches because the order in which you notice things often determines whether you misdiagnose the cause.
- April 16, 2026: Anthropic releases Claude Opus 4.7 to general availability.
- Right after launch: Claude Code replies stopped using their usual polite tone and felt more clipped. Almost in parallel, I noticed token balances draining much faster than usual.
- Trying to isolate the cause: I suspected something on my side first — restarted the session, experimented with
/effortvalues, and compared outputs. That experimentation made it clear the change was server-side, not in my local setup. - Confirmation: A few days later, news of Anthropic adjusting the output-shortening system prompt landed, which lined up with what I had been seeing, and the rough edges in tone smoothed out again.
🏆 Author’s take ― “make it shorter” optimizations rarely play well with quality
Optimizing a frontier model toward shorter outputs sounds appealing — fewer tokens billed, snappier UX. In practice it tends to clip the explanatory steps and the careful tone that make answers feel reliable, and it shows up as “the model got dumber.” Reverting the output-shortening prompt was the right call; reliability beats marginal cost savings on a tier like Opus.
⚠️ Before blaming the model, check these
- Output tone (polite vs. clipped, replies that end as raw bullet lists)
- Recent token consumption trends (a 2–3× spike is your warning signal)
- The current value of
/effort(highormediumfor everyday work) - Session context length (very long history also degrades quality)
Three migration pitfalls to clear first
Switching the model ID is a one-liner, but Opus 4.7 ships with three changes that quietly break code or budgets if you do not plan for them. If you maintain anything that talks to the API, plan to clear these three before you flip the switch in production.
1. The new tokenizer raises real cost
Opus 4.7 ships with a new tokenizer, and external reviews observe up to ~35% more tokens for the same code-heavy text compared with Opus 4.6. Per-token pricing is unchanged, but the tokens themselves are more expensive in aggregate. Run a small set of representative tasks through both models and update your monthly cost forecast before you shift production traffic.
2. Old API parameters now return 400
Opus 4.7 retires thinking.budget_tokens, temperature, and top_p. Calls that still set them now return 400 errors. Reasoning budget is expressed via the /effort tiers (low, medium, high, xhigh, max) instead. Anthropic ships a migration helper through Claude Code that handles most of the mechanical changes for you; pairing it with a manual review of any prompt logic that depended on low-temperature determinism is usually enough.
3. Reasoning summaries are hidden by default
The default of thinking.display changed to omitted. Any UI that used to show a reasoning summary will render an empty section unless you explicitly opt in to summarized (or another mode). For products that surface chain-of-thought to users, this looks like a rendering bug, but it is just the new default.
Three settings to verify right now
If you plan to lean on Opus 4.7 for serious work, treat the launch as a forcing function and re-calibrate your environment once instead of trusting that defaults still match your expectations. Three checks cover most of the failure modes.
① Current /effort tier
Check with /effort. I run on medium daily and only step up for genuinely heavy tasks.
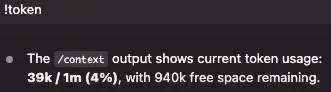
② Token usage trend
Same prompts cost very different token amounts at different tiers. A sudden 2–3× jump is your cue to recheck settings.
③ Model switch behavior
Point the API at claude-opus-4-7, remove deprecated parameters, and re-baseline cost on a slice of traffic.
If you are pushing limits on the Max plan, the trade-offs are worth pairing with our deeper Claude Max plan value analysis. The right /effort per task is one of the biggest levers for staying inside your usage envelope.
How Opus 4.7 sits next to GPT-5.4 and Gemini 3.1 Pro
Opus 4.7 does not win on every axis. External head-to-heads put Opus 4.7 ahead on agentic coding, document and diagram parsing, and long-running agent runs, while GPT-5.4 retains an edge on very long context and certain real-time vision tasks, and Gemini 3.1 Pro continues to lead on extreme context length. Anthropic itself is explicit in the model card that Opus 4.7 is less capable than the unreleased Claude Mythos. Treat Opus 4.7 as the strongest publicly available all-rounder for now, and combine it with other models — including Sonnet variants and competitor models — based on the workload.
Should you upgrade to Opus 4.7?
For most Claude Code and Cowork users, the upgrade to Opus 4.7 is a straightforward yes. Pricing is unchanged, the gains on hard coding, self-verification, and long-running tasks are tangible, and the launch-time output-shortening behavior has already been adjusted server-side.
Teams who routinely struggle with multi-file refactors, or who run long autonomous agent jobs through Cowork or Claude Dispatch, will see the largest benefit. For light Q&A, short coding chats, and reaction-speed-sensitive interactive coding I personally still mix in Sonnet — it tends to give a better cost/latency profile in those slots. Treat /effort selection and model selection as part of the same decision, not as an afterthought.
Regression points to keep an eye on
External reviews flag two real regressions in Opus 4.7. Long-context recall — the classic “lost in the middle” problem — gets worse on prompts above ~100K tokens, which matters for whole-codebase analyses, financial reports, and long contracts. Adherence to strict, zero-shot formatting instructions (rigid JSON schemas, exact markdown templates) also slips slightly. If your workflow lives in those zones, A/B Opus 4.7 against Opus 4.6 and Sonnet on real samples before you fully migrate. This is exactly why /effort tuning needs to be paired with per-task model selection rather than treated as a global default.
📝 Author’s take ― make calibration a launch ritual
The Opus 4.7 launch was a useful reminder that “model upgrade” is never just about the model. Server-side system prompts, the default behavior of the client, the /effort tier, and how you measure tokens all matter. For future Opus releases, I will keep treating “re-baseline tone, /effort, and token consumption” as a small but mandatory ritual before drawing conclusions.
Frequently asked questions
Summary
- Claude Opus 4.7 became generally available on April 16, 2026 with no price change and clear gains on hard coding, self-verification, long-running tasks, and vision.
- The “blunt replies” complaint came from Anthropic’s output-shortening system prompt and has been adjusted server-side; the “exploding tokens” complaint is a separate story driven by the new tokenizer and effort-tier behavior.
- Migration cost lives in three places: real spend (new tokenizer), API breakage (
thinking.budget_tokens,temperature,top_pare gone), and hidden reasoning summaries (thinking.displaydefaults toomitted). - Confirm your
/efforttier first; usemediumorhighdaily and reservexhighfor genuinely hard tasks. For long-context or strict-format workloads, A/B Opus 4.7 against Opus 4.6 and Sonnet before fully migrating.
Opus 4.7 pays off when model switch, /effort calibration, and API cleanup ship together
Same price, sharper Opus. The teams that benefit most are the ones who pair the model upgrade with a one-time review of /effort, token consumption, and deprecated API parameters.







Author
krona23
Over 20 years in the IT industry, serving as Division Head and CTO at multiple companies running large-scale web services in Japan. Experienced across Windows, iOS, Android, and web development. Currently focused on AI-native transformation. At DevGENT, sharing practical guides on AI code editors, automation tools, and LLMs in three languages.



Leave a Reply