
Claude Opus 4.7 が 2026 年 4 月 16 日に一般提供開始されました。Opus 4.6 から「自己検証」「長時間タスク」「視覚処理」「難問コーディング」で明確に強化された一方、リリース直後には Claude Code 上で「応答が丁寧語ではなくなった」「トークン使用量が急激に増えた」という 2 つの違和感が同時に発生し、ユーザーの間で精度低下の話題が広がりました。
📑目次
筆者の理解では、これら 2 つは別の事象です。「ぶっきらぼうさ」は Anthropic が出力トークンを短くする方向のシステムプロンプトを追加したことの副作用、「トークン爆増」は /effort 設定や新トークナイザーが絡む別の話で、たまたま同じタイミングで重なって体感されただけと見ています。本記事では、まず Opus 4.7 で本当に強化された点を整理し、次にこの 2 つの違和感の正体と Anthropic の対応、そして移行時の落とし穴・いま確認すべき設定までを実体験ベースでまとめます。
| 観点 | Opus 4.6 | Opus 4.7 |
|---|---|---|
| 難問コーディング | 標準 | 内部 93 タスクで +13%、SWE-bench Verified 87.6%(公表値) |
| 自己検証 | 限定的 | 出力前にロジックを自己点検 |
| 長時間タスク | 一定の安定性 | 一貫性と完遂率が向上 |
| 視覚処理 | 標準解像度 | 最大 2576px / 3.75MP の高解像度入力 |
| API 価格(入力/出力) | $5 / $25 per Mtok | $5 / $25 per Mtok(据え置き) |
| 実コスト傾向 | 基準 | 同価格でも新トークナイザーと higher effort 既定で実消費は増えやすい(最大 +35% の観測例あり) |
| API モデル ID | claude-opus-4-6 | claude-opus-4-7 |
出典:Anthropic 公式アナウンス、Karo Zieminski の独自テスト記事(2026年4月時点)
Claude Opus 4.7 とは|2026年4月16日リリースの最新 Opus
Claude Opus 4.7 は、2026 年 4 月 16 日に Anthropic が一般提供を開始した最新の Opus モデルです。同社の公開モデル群としては現時点でもっとも強力ですが、社内にはさらに上位の Claude Mythos(公開を限定している研究プレビュー)が存在し、Opus 4.7 はあえて Mythos より能力を抑えたうえで安全策を実証する位置づけとして公開されました。
提供チャネルは Claude.ai・Anthropic API・Amazon Bedrock・Google Cloud Vertex AI・Microsoft Foundry と幅広く、API モデル ID は claude-opus-4-7。価格も Opus 4.6 と同じく入力 $5 / 出力 $25 per million tokens で据え置かれています。既存の Opus ユーザーは、コードを書き換えずにモデル ID を切り替えるだけで移行できます(ただし後述のとおり、同時に廃止された API パラメータには注意が必要です)。
公式アナウンスは Introducing Claude Opus 4.7 で確認できます。料金プランの詳細を整理したい場合は Claudeの料金プラン徹底解説 も合わせて参照してください。
Opus 4.7 で強化された 4 つのポイント
Opus 4.7 の強化は「コーディング・自己検証・長時間タスク・視覚処理」の 4 点に集約されます。それぞれ公式発表と早期テスターのコメント、外部レビューの観測値を踏まえて整理します。
1. 難問コーディングでの精度向上
Anthropic 内部の 93 タスクコーディングベンチマークでは、Opus 4.6 比で約 13% の解決率向上が報告されています。「Opus 4.6 でも Sonnet 4.6 でも解けなかった 4 タスクを Opus 4.7 が解いた」というコメントもあり、外部レビューでも SWE-bench Verified が 87.6% 前後に達したという観測値が出ています。大規模リファクタリングや複数ファイルにまたがるロジック修正で体感差が出やすいモデルです。
2. 自己検証(Self-verification)の強化
Opus 4.7 は出力する前に、自分のロジックや前提条件を点検する挙動が強化されています。データ分析プラットフォームの Hex はコメントの中で「もっともらしいが間違っているフォールバックを返さず、データが不足していれば率直に『データがない』と報告できる」と評価しており、Anthropic 自身も「Opus 4.6 や Sonnet 4.6 と比べて重要な情報の欠落が大きく減り、ハルシネーション率も低下した」とモデルカードで公表しています。
3. 長時間・マルチステップタスクの一貫性
CI/CD 連携や非同期ワークフローなど、何時間も走らせるエージェント運用で破綻しにくくなった点も大きな改善です。Devin の事例コメントでは「以前は信頼できなかった深掘り調査タスクが回るようになった」と紹介されており、Claude がPCを自動操作する時代|Dispatch・Computer Use・Loop・Channels 全機能解説 で取り上げた自律エージェント機能との相性も良いモデルです。
4. 高解像度の視覚処理
視覚処理では入力画像の最大解像度が 2576px / 3.75MP に拡張され、図表・化学構造・特許図面・複数列レイアウトの PDF など、細部を読む業務での精度向上が報告されています。スクリーンショットを使った Claude Code の UI デバッグ 用途でも、これまで読み取れなかった小さな文字や複雑なレイアウトに対応しやすくなりました。
5. 据え置き価格でも「実質値上げ」になり得る点
Opus 4.7 は価格こそ据え置きですが、「同じ仕事を頼むと請求額が増える」現象が起こり得ます。Anthropic 自身が「Opus 4.7 は higher effort で動くため、Opus 4.6 より出力トークンが増える」と移行ガイドで明言しており、外部レビューでも新トークナイザーで同じ文章のトークン量がコード中心のプロンプトで最大 35% 増えるという観測値が出ています。価格表だけ見て移行コストを見積もるとズレるため、サンプルタスクで実トークン数を計測しておくのが安全です。
🏆 筆者の見解 ― 素の強化と運用上の負担を分けて評価する
体感としては「コーディング・自己検証・視覚」の伸びは確かに感じられます。一方で「同じ価格表でも実コストは上振れしやすい」「リリース直後の挙動変動」といった運用面のクセが乗ってくるため、素の品質と日々の請求額・体感は別物として評価するのが安全です。
利用してみた実感|「ぶっきらぼう」と「トークン爆増」は別問題
結論から書くと、Opus 4.7 リリース直後に発生した違和感は 2 つあり、それぞれ原因が違います。混同するとモデルそのものが劣化したように見えてしまうので、まずここを切り分けます。
- 「応答がぶっきらぼう」… 筆者の理解では、Anthropic が出力トークンを短くする方向のシステムプロンプトを追加したことの副作用です。回答が丁寧語ではなくなり、文体が素っ気なくなった一方で、論理の精度自体も下がる場面が見られたため、Anthropic 側で修正が入りました。
- 「トークン使用量が急増」… こちらは別の話で、新トークナイザーで同じ内容でもトークン数が増えやすくなったこと、そして
/effortなど思考予算側の挙動が積み上がった結果と捉えています。価格表上の単価は同じでも、請求は確実に上振れしやすくなっています。
筆者の環境では、リリース直後に Claude Code の応答が「丁寧語ではない、ぶっきらぼうな書き方」になっていることに先に気づき、ほぼ同時にトークンの残量を確認したところ、いつもより明らかに急速に減っていました。「同じ Opus 4.7 という名前だから同じ問題のはず」と思いがちですが、ふたを開けてみるとシステムプロンプト由来の話と、トークナイザー・思考予算由来の話が重なっていた、という整理が一番しっくりきています。

そもそも /effort とは何か
/effort は、Claude Code の効率化テクニック でも触れている、推論にかける思考予算を切り替えるスラッシュコマンドです。代表的な段階は low / medium / high / xhigh / max で、段階を上げるほど内部推論の深さ・トークン消費・レイテンシが増えます。Opus 4.7 で新たに xhigh が high と max の中間段として明確に位置づけられました。
早期テスターの中には「low-effort Opus 4.7 ≒ medium-effort Opus 4.6」と評する声もあり、Opus 4.7 ではむしろ思考予算を 1 段階下げても十分な品質が出るケースが多いと感じます。筆者自身も普段使いは medium に落ち着いており、大規模リファクタや複数ファイル横断のバグ修正、長文記事の構成のように本当に重い作業だけ段階を上げる運用にしています。
事の顛末|気づき・対処・修正までの流れ
Opus 4.7 のリリース直後、筆者は次のような順序で違和感を消化しました。記録として残しておくと、似た状況に遭遇した読者の判断材料になりそうなので、率直に並べます。
- 2026-04-16: Anthropic が Claude Opus 4.7 を一般提供開始。
- リリース直後(同日〜数日): Claude Code の応答トーンが普段と変わり、丁寧語ではない素っ気ない書き方が増えた。同時にトークン残量を確認したところ、普段より急激な減りを観測。
- 切り分けの試行: 設定が壊れた可能性を疑ってセッションを再起動したり、
/effortの値をいじって挙動を比較。この過程で「これは自分の環境ではなく、サーバー側の挙動が変わっているらしい」と気づく。 - 修正の確認: 後日のニュースで、Anthropic 側が出力短縮系のシステムプロンプトを修正した旨が報じられ、自分の手元の挙動とつじつまが合う形で違和感が落ち着いた。
🏆 筆者の見解 ― 「短く返させる」最適化はモデル品質と相性が悪い
Opus 4.7 ではコスト最適化と品質のバランスが繊細に絡みます。出力トークンを短くする方向のシステムプロンプトは、理屈の上では請求を抑えますが、論理の途中経過や前提確認まで省略され、結果として「ぶっきらぼう」かつ「精度が落ちた」と感じさせる場面が出ました。Anthropic がこの方向の最適化を撤回したのは、コストよりも信頼性を優先した判断として妥当だったと受け止めています。
⚠️ 「精度が下がった」と感じたら最初に疑うこと
- 出力トーン(丁寧語かどうか・極端に短い箇条書きで終わっていないか)
- 直近のトークン使用量の推移(普段の 2〜3 倍は要注意)
/effortの現在値(普段使いはhighまたはmedium推奨)- セッションのコンテキスト長(過剰な履歴も応答品質に影響)
移行時にハマる 3 つの落とし穴
Opus 4.7 はモデル ID を切り替えるだけで使い始められますが、「動くけれど期待どおりではない」状況に陥りやすい落とし穴が 3 つあります。API 経由で組み込んでいるサービスを抱えている場合は、移行作業の最初に潰しておくのがおすすめです。
1. 新トークナイザーで実コストが増える
Opus 4.7 はトークナイザーが新しくなり、特にコード中心のプロンプトでは同じテキストでも従来比で最大 35% 程度トークンが増える観測例があります。価格表の単価は同じでも、請求額は素直に増える方向に動きます。移行時にいくつかのサンプルタスクで実トークン数を計測し、月次のコスト試算を更新しておくと安全です。
2. 旧 API パラメータが 400 エラーになる
Opus 4.7 では thinking.budget_tokens・temperature・top_p などのパラメータが廃止され、指定すると 400 エラーが返ります。思考予算は /effort 相当の low / medium / high / xhigh / max で表現する形に統一されました。これらのパラメータを使っていたコードは、まずパラメータ削除と effort 指定への置き換えが必要です。Anthropic は移行支援用の Skill も提供しているため、Claude Code を併用しているならそちらに任せるのが速いです。
3. 推論サマリーが既定で非表示になる
thinking.display の既定値が omitted に変更され、これまで表示していた推論サマリーが何も指定しないと UI 側で空白に見えます。推論過程をユーザー向けに表示している自社プロダクトを持っている場合、レンダリングが壊れたように見えるため、移行前に summarized 等を明示する設定変更が必要です。
今すぐ確認すべき 3 つの設定
Opus 4.7 を腰を据えて使うなら、リリース直後の混乱を踏まえて自分の環境を一度キャリブレーションしておくのがおすすめです。確認すべきポイントは 3 つあります。
① /effort の現在値
セッションで /effort を確認。筆者は普段 medium で運用し、難所だけ段階を上げています。
② トークン使用量の推移
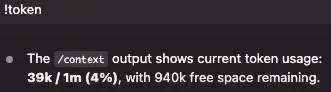
同じプロンプトでも段階を上げると消費は数倍に。普段の 2〜3 倍に跳ねたら設定の変動を疑う。
③ モデル切替の挙動
API 利用なら ID を claude-opus-4-7 に切替し、廃止パラメータを除去。一部タスクから移行してベースラインを取り直す。
Max プランの上限内に収めたい場合は、Claude Max プランに加入する価値はあるか? で整理した使い方も合わせて確認しておくと、/effort の段階選びの判断軸がはっきりします。
他社モデルとの立ち位置|GPT-5.4・Gemini 3.1 Pro との関係
Opus 4.7 はあらゆる軸で他社モデルに勝つわけではありません。外部レビューを横に見ると、コーディングや視覚処理、長時間エージェント運用では Opus 4.7 が優勢な一方、超長文コンテキストや一部のリアルタイム視覚タスクでは GPT-5.4 や Gemini 3.1 Pro が依然として有利な領域があります。Anthropic 自身も「Opus 4.7 は Claude Mythos には届かない」とモデルカードで明言しており、Opus 4.7 を「現時点で公開されている強力なオールラウンダー」と位置づけ、用途ごとに他社モデルや Sonnet 系と組み合わせる発想が現実解です。
結局、Opus 4.7 にアップグレードすべきか
結論として、Claude Code や Cowork を日常的に使う多くのユーザーにとって、Opus 4.7 へのアップグレードは素直に推奨できます。価格据え置きで、難問コーディング・自己検証・長時間タスクの安定性が伸びている上、リリース直後の出力短縮系の挙動はすでに修正済みだからです。
大規模リファクタや複数ファイルにまたがるバグ修正で詰まりがちな方、長時間自走させる Cowork や Claude Dispatch 用途のユーザーは、Opus 4.7 への移行で恩恵が大きいはずです。一方、軽い質問や短い対話、コーディング中のリアクション重視の場面では筆者も Sonnet 系を併用しており、コストとレスポンス時間のバランスではそちらの方が回しやすい場面が確かにあります。/effort の段階と組み合わせ、タスクごとに切り替える運用がもっともコストパフォーマンスに優れます。
Opus 4.7 で気をつけたい回帰ポイント
外部レビューでは、Opus 4.7 で「悪化した」面も指摘されています。代表例は 100K トークン超の長文コンテキストでの「lost in the middle」傾向の悪化と、厳密な JSON スキーマや細かいフォーマット指示への追従度のわずかな低下です。財務レポート・契約書・大規模リポジトリ全体を読ませる用途や、ゼロショットで厳密フォーマットを強制したい用途では、いったん Opus 4.6 の方が安定するケースもあるため、移行前にテストデータで挙動を比べるのが安全です。だからこそ /effort と並んで「タスクごとのモデル選択」も意識しておきたいポイントです。
📝 筆者の見解 ― リリース直後はキャリブレーションを習慣に
Opus 4.7 のリリースは「モデルの強化」と「サーバー側システムプロンプトの調整」「クライアント側のデフォルト挙動」を同時に意識しないと正しく評価できないリリースでした。今後の Opus シリーズでも、リリース直後の挙動を盲目的に信じるのではなく、/effort とトークン消費を一度キャリブレーションする習慣をおすすめします。
よくある質問(FAQ)
まとめ
- Claude Opus 4.7 は 2026 年 4 月 16 日に一般提供開始。価格据え置きで難問コーディング・自己検証・長時間タスク・視覚処理が強化されました。
- リリース直後の「ぶっきらぼう」は出力短縮系のシステムプロンプト由来で、Anthropic 側で修正済み。「トークン爆増」は新トークナイザーや思考予算の影響で、別問題として整理しておくと混乱しません。
- 移行時は新トークナイザーによる実コスト増、廃止パラメータ(
thinking.budget_tokens/temperature/top_p)、thinking.display既定変更の 3 点を最初に潰しておきます。 - 普段使いの
/effortはmediumあたりに据え、難所だけ段階を上げる。長文コンテキストや厳密フォーマット用途では Opus 4.6 や Sonnet 系の併用も視野に入れて運用しましょう。
Opus 4.7 は「モデル切替+設定キャリブレーション+API 整理」で真価を発揮する
価格据え置きで強化された Opus 4.7 を最大限活かすには、リリース直後の挙動を自分の環境で一度確認し、/effort・トークン消費・廃止パラメータを整える習慣を持つことが鍵です。







著者
krona23
IT業界20年以上の実務経験を持ち、日本国内有数のPVを誇る大規模Webサービスで事業部長・CTOを複数社で歴任。Windows/iOS/Android/Webと技術の変遷を経験し、現在はAIネイティブへの変革に注力。DevGENTでは、AIコードエディタ・自動化ツール・LLMの実践的な使い方を日英西3言語で発信中。



コメントを残す